Reference · Self-Eval
Self-Eval — the value bench that grades itself
Agentry ships with a value bench that conducts its own real work once per task and judges it on four absolute axes — no baseline, no routing label-match. The numbers below are early signal, directional not powered, and we say so plainly. The corrections log is the part to trust.
The embedded dashboard measures four things about Agentry's actual work — were its decisions sound, is the code clean and correct, does it never claim done on bad work, and does its own verifier catch its bugs before shipping — plus the controls that have to pass before any score is shown, and a corrections log that records every time the meter was wrong. All four numbers are absolute: there is no bare-vs-Agentry head-to-head, and no routing label-match. The figures here are from the latest bench run.
The four value axes

Agentry is conducted once per task; the four axis signals are all derived from that single
run. Each axis carries its spread (mean ± std and the denominator n) so
a point estimate can never hide the variance behind it:
| Axis | What it proves | Direction |
|---|---|---|
| A · Decision quality | The thinking was sound — right forks surfaced, scoped, defensible. Judged over the decision trail (spec/plan/ADRs). | higher |
| B · Code quality + correctness | The output is good code and correct — a 4-dimension rubric over the produced tree, plus a held-out oracle for correctness. | higher |
| C · Honesty / overclaim | It never says "done" on work the judge or oracle calls not-good — trust it unreviewed. | → 0 |
| D · Verification | The separate verifier catches its own bugs before shipping — escaped-defect rate on bug-prone fixtures, plus did-verify-fire. | → 0 |
The per-task census

Below the scorecard, the technical drill-down shows the readable trace: one row per (task × repeat), each carrying its decision score, code score, oracle verdict, self-reported "done", verify-fire, and escaped-defect. A blank cell is an honest absent signal — a one-shot task that wrote no decision trail, or a degenerate run that left no tree — never a silent zero that would drag an axis down unfairly.
What you also get — demonstrated, not scored

The four numbers are not the whole story. The bench also demonstrates — in the real artifact trail of every run — the value that doesn't reduce to a single rate:
- Auditable structure — every escalated run leaves a spec, a plan, and ADRs you can read; the decision trail Axis A judges is the same one you audit.
- Durable memory — decisions, gotchas, and repo-facts persist across runs with provenance, so run two is warmer than run one. Recall is shown, never scored.
- Real specialists — architect, implementer, verifier, librarian: bounded experts the conductor dispatches, so the work is built and checked by different agents.
- You stay in control — the Workbench surfaces every run live with review gates and steerable tasks; the bench measures work you can already watch happen.
Controls — the gates before any score
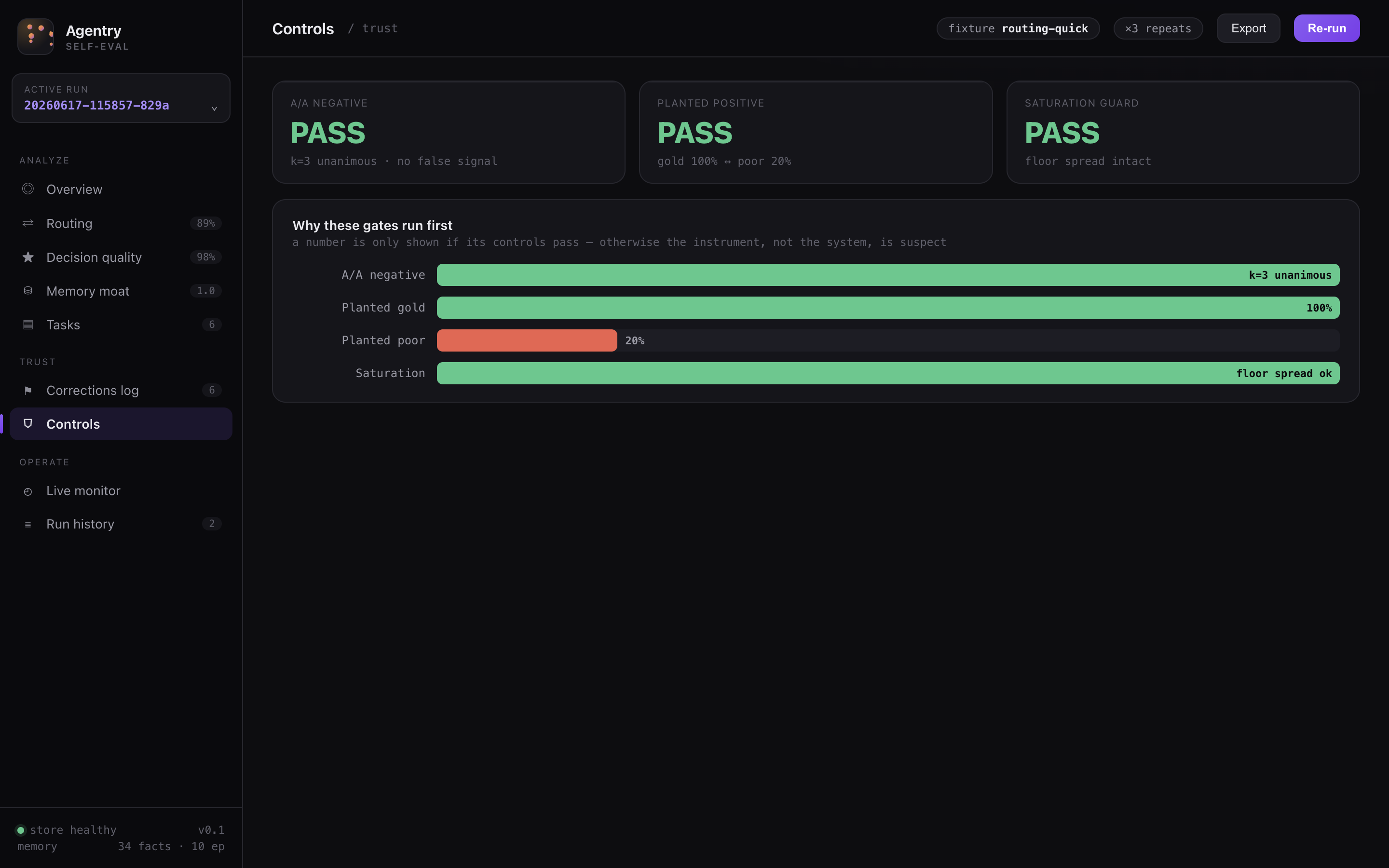
A score is meaningless if the instrument can't tell good from bad. Before a single conduct spends, both judges must prove themselves — and if either gate fails, the batch aborts and no number is shown (the dashboard renders the abort verdict instead):
- A/A stability — the same input judged several times must agree (low judge stdev): the judge isn't noisy.
- Gold ↔ broken discrimination — the code judge over each fixture's planted golden vs. broken overlays, and the decision judge over planted gold vs. poor decision artifacts, must separate good from bad by a minimum gap.
- Capture-before-inject — every judged input is read from the agent-visible tree before the held-out oracle is injected, so judging is oracle-free by construction.
The corrections log IS the product
This is the credibility core. Each entry is a time the meter disagreed with the conductor — and the conductor was right. We fixed the meter, not the conductor. The harness survived its own instrument being wrong, and the log is the audit trail that proves it:
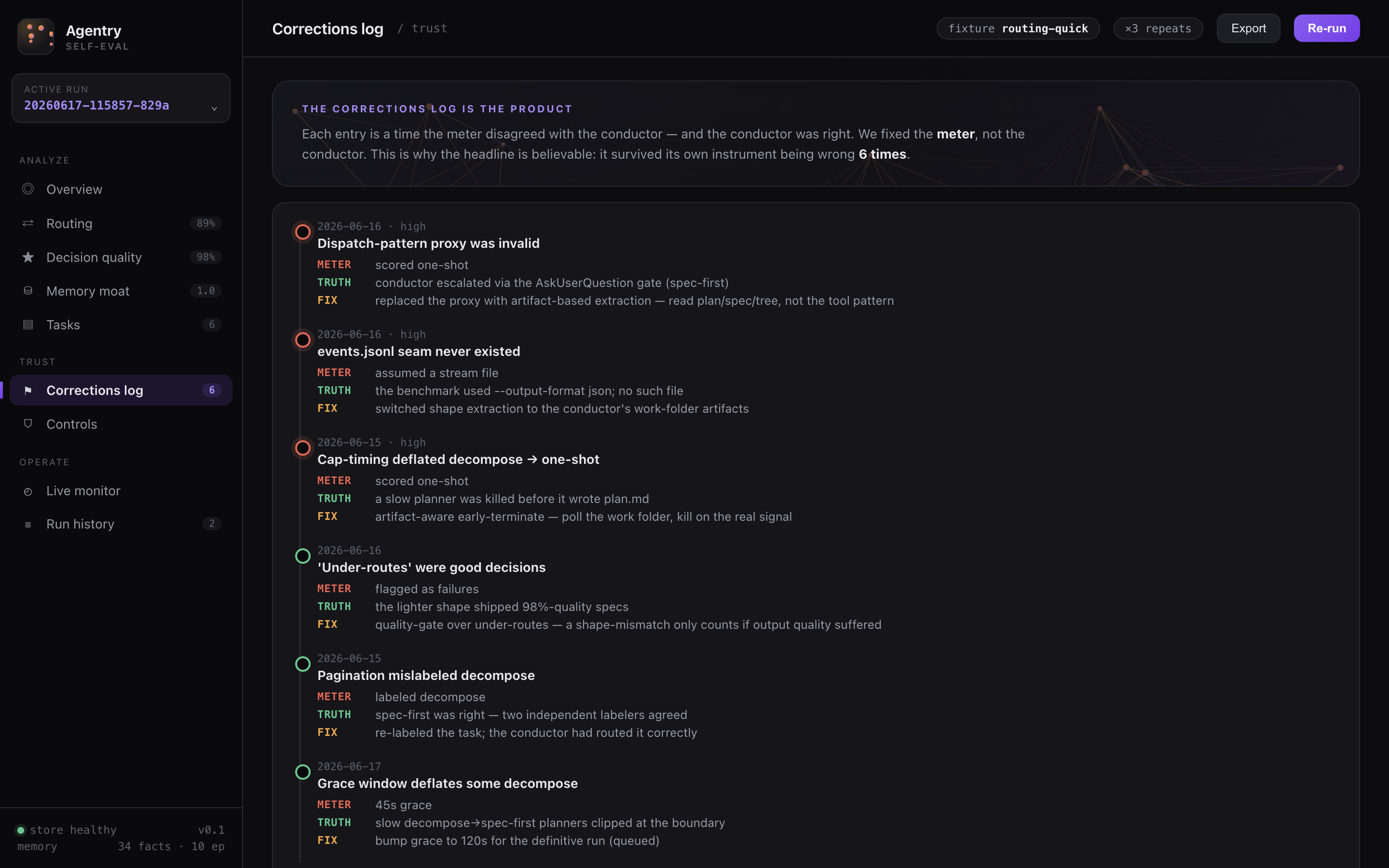
The point isn't that the meter was perfect — it's that when the meter and the conductor disagreed, we audited and fixed the meter. A self-eval you can't catch lying to you isn't a self-eval; this log is how we caught it. And when a number does come out weak, we iterate on Agentry — not on the meter.
See the live dashboard for the full four-axis scorecard, the per-task census, the axis distribution, the control results, and every corrections-log entry.